1. 实验要求
- 做一个生物识别应用~
2. 实验过程
后来还是没忍住蹭了实验室的CUDA,这是背景,但是蹭了又没完全蹭,后来还是CPU硬顶上
处理数据:原始数据48x48已经相当友好,只需要归一化(试了一下opencv先均衡化,效果稀烂😓)
搭建CNN网络:基本上只要有一丢丢torch的基础,这一步蛮套路的,像是搭积木🤪
class FaceCNN(nn.Module):
def __init__(self):
super(FaceCNN,self).__init__()
# 卷积、池化
self.conv1=nn.Sequential(
nn.Conv2d(in_channels=1,out_channels=64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=64), # 归一化
nn.RReLU(inplace=True), # 激活函数
nn.MaxPool2d(kernel_size=2, stride=2),# 最大池化
)
# 第二次卷积、池化
self.conv2 = nn.Sequential(
# input:(bitch_size, 64, 24, 24), output:(bitch_size, 128, 24, 24), (24-3+2*1)/1+1 = 24
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=128),
nn.RReLU(inplace=True),
# output:(bitch_size, 128, 12 ,12)
nn.MaxPool2d(kernel_size=2, stride=2),
)
# 第三次卷积、池化
self.conv3 = nn.Sequential(
# input:(bitch_size, 128, 12, 12), output:(bitch_size, 256, 12, 12), (12-3+2*1)/1+1 = 12
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=256),
nn.RReLU(inplace=True),
# output:(bitch_size, 256, 6 ,6)
nn.MaxPool2d(kernel_size=2, stride=2),
)
# 全连接层
self.fc = nn.Sequential(
nn.Dropout(p=0.2),
nn.Linear(in_features=256 * 6 * 6, out_features=1024),
nn.RReLU(inplace=True),
nn.Linear(in_features=1024, out_features=256),
nn.RReLU(inplace=True),
nn.Linear(in_features=256, out_features=7),
)
# 前向传播
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
# 数据扁平化
x = x.view(x.shape[0], -1)
y = self.fc(x)
return y训练:emm没有cuda加速真的就是别人两分钟俺要跑一天,调参还有debug都很不方便!😇
应用:因为需要调用摄像头,还是走了一点弯路的,具体看下文。我的思路是训练好的模型保存成.pkl方便后续调用
2.1 各种bug
1、首先是训练过程报错:log_softmax_lastdim_kernel_impl" not implemented for 'Long',解决方法是查看tensor数据类型,改成long()或者torch.float32,一定先查看自己的类型再个性化修改,网上高赞直接照做的话木用的哇
BUG:解决方案
2、然后是调用摄像头:
之前Django做过类似的项目,所以这边还算简化(因为不需要将模型部署网页所进行的图片流操作嘛),之前网页没有解决关闭摄像头的问题,这次解决了,其实也不难,就是懒癌啊哈哈
def OpenVideoTest():
cap = cv2.VideoCapture(0)
while cap.isOpened():
ret, frame = cap.read()
cv2.imshow('windowName', frame)
# 点击小写字母q 退出程序
if cv2.waitKey(1) == ord('q'):
break
# 点击窗口关闭按钮退出程序
if cv2.getWindowProperty('windowName', cv2.WND_PROP_AUTOSIZE) < 1:
break
# 人脸识别获取图像……
# 调用模型,实时操作……
cap.release()
cv2.destroyAllWindows()3、关于模型的超参数等的优化问题
只能说自己是一个调参业余选手了叭,一开始数据集处理那边用Opencv的一些工具(直方图等等操作,然而没啥效果),导致特别耗时间(具体可以看data_utils中Dataset的写法),后来改成了常规写法具体见all.py,速度快了不少(指CPU运行从一整天到大半天的”进步“)
调参的化优化器一开始用的SGD效果不理想,后来还是无脑Adam,Adam yyds!
3. 展示
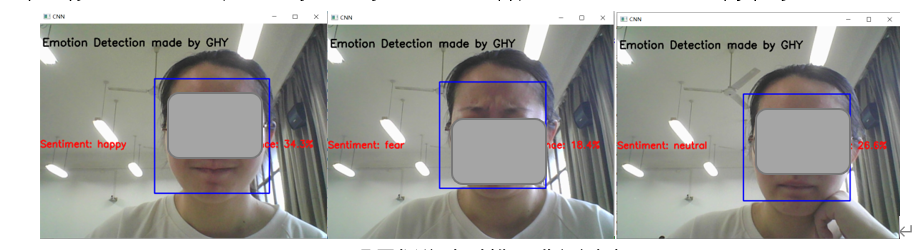
当然是选好的放报告上啦~虽然train正确率72%,val正确率71%,但是真正落地的时候嘛,完美诠释”间歇性人工智障“。
后来我自己做了一些自己的图片插进去做训练了,结果还没跑出来,就酱叭~
4. 碎碎念
这个作业怎么说捏,昂,压在三门考试之间就比较窒息叭。我给自己三天完完整整的时间做,本来想说蹭一下实验室资源,但是老师说需要可视化……可视化只能在本地调用本地摄像头的话,在模型训练环境和运行环境之间折腾了蛮久。后来实验室那边资源好像不够,就完全转CPU啦,emmmmm觉得不是明智之举。



