1. 论文阅读报告
复现这个工作的好多吖,感觉属于比较经典?~
[[code]](Incorporating Copying Mechanism in Sequence-to-Sequence Learning | Papers With Code)
考古使我快乐🧐
1.1 Abtract
- 基于Seq2Seq架构(encoder-decoder)
- 创新点:其中输入序列中的某些片段在输出序列中被选择性地复制(所以叫copyNet😋)
1.2 Motivation

- 常规的encoder-decoder架构以及它们的变体都“严重”依赖于“含义”,在系统需要复述“时间”“实体“的时候表现不佳
- 鉴于人类本身也有”死记硬背“的特性,我们认为”理解“+”背诵“可以使得Seq2Seq的性能更好
1.3 Models
1.3.1 模型总览

Encoder:常规操作,利用RNN将输入的单词序列${x_1,x_2……x_t}$转化为等长的${h_1,h_2,……h_t}$,这里为了方便描述将后者表示为$M$
Decoder:操作比较多
- 预测:分成两个模块(
生成模块(generate mode)和拷贝模块(copy mode,详见下文🎫展开,利用到了前文的M)) - 状态更新:在更新$t$时刻的单词时候用到了$t-1$时刻的状态,除此之外还用到$M$对应位置的状态(详见下文👕展开)
- 关于对于$M$的阅读:除了基于注意力机制下对于$M$的阅读,还对于$M$进行选择性的阅读,这导致了对于内容的寻址和对于位置寻址的强大混合
1.3.2 亿些细节
1.3.2.1 🎫细节一
对于输入序列$X$,我们的词表是$V$∪$UNK$∪$\chi$
其中$V$是预定义的全局词表,$UNK$代表未知词,$\chi$代表输入序列本身产生的词表
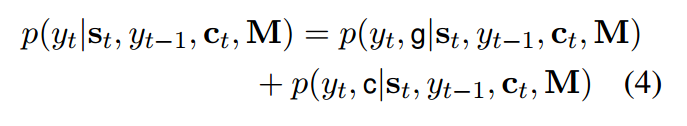

我的理解:有点像是构造了一个四分类器,根据$y_t$的情况对概率的计算做出调整
- 目标词$y_t$如果属于词汇表或者源端,就分别计算上述两个概率;
- 如果既不属于词汇表,也不属于源端,就是UNK;
- 如果属于源端,但不属于词汇表,那么生成的概率为0;
- 如果不属于源端,那么复制的概率为0。Z是两种模式共享的归一化项

两种模式分数的计算方法:

1.3.2.2 👕细节二
decoding过程中$s_t$状态由上一个时刻的状态$s_{t-1}$、上一个时刻的目标词表示$y_{t-1}$和内容集合$c_t$决定,创新点在于$y_{t-1}$将被$[e(y_{t-1};\zeta(y_{t-1}))]^T$代替
其中$\zeta(y_{t-1})$代表着对于$M$的选择性读取
具体展开详见论文
1.4 Experiment
1.一个具有简单模式的合成数据集;
2.一个关于文本摘要的真实任务;
3.一个用于简单的单回合对话的数据集
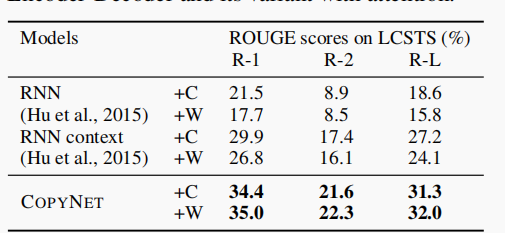
1.4.1 实验结果


2. 参考资料
3. 碎碎念
主要是研训本来的任务没有结束,所以Web系统实现得差不多了,就回过头来继续”啃“这个骨头啦~
在系统搭建过程中进一步巩固了自己编程能力叭,有了万行代码量加持,现在觉得论文复现的工程量其实还🆗😜


