1 词法分析器
1.1 设计要求
您必须使用DFA(确定性有限自动机)或NFA(不确定性有限自动机)来实现此程序。 程序有两个输入:
一个文本文档,包括一组3语法(正规文法)的产生式;
一个源代码文本文档,包含一组需要识别的字符串。 程序的输出是一个token(令牌)表,该表由5种token组成:关键词,标识符,常量,限定符和运算符。
*词法分析程序的推荐处理逻辑*
根据用户输入的正规文法,生成NFA,再确定化生成DFA,根据DFA编写识别token的程序,从头到尾从左至右识别用户输入的源代码,生成token列表(三元组:所在行号,类别,token 内容)
*要求*
- 词法分析程序可以 准确识别 科学计数法形式的常量(如0.314E+1),复数常量(如10+12i)
- 可检查整数产量的合法性,标识符的合法性(首字符不能为数字等)
- 尽量符合真实常用高级语言(如C++、Java或python)要求的规则
1.2 设计思路
NFA->DFA识别词语Token
1.3 实验结果展示
主要是简单的显示一下设计思路,参考C++语法设计的正规文法作为输入,因此部分细节可能有所疏漏
input.txt
[START] --> ['_'][A]
[START] --> [letter][A]
[A] --> [letter][A]
[A] --> [number][A]
[A] --> ['_'][A]
[A] --> [final]
[START] --> ['+'][B]
[START] --> ['-'][B]
[START] --> [number][B]
[START] --> [number][C]
[B] --> [number][B]
[B] --> ['.'][C]
[B] --> [number][C]
[C] --> [number][C]
[C] --> [final]
[B] --> [final]
[START] --> ['+'][D]
[START] --> ['-'][D]
[START] --> [number][D]
[D] --> [number][D]
[D] --> ['.'][E]
[D] --> [number][E]
[E] --> [number][E]
[E] --> ['E'][F]
[E] --> ['e'][F]
[F] --> ['+'][G]
[F] --> ['-'][G]
[F] --> [number][G]
[G] --> [number][G]
[G] --> [final]
[START] --> ['+'][H]
[START] --> ['-'][H]
[START] --> [number][H]
[H] --> [number][H]
[H] --> ['.'][I]
[H] --> [number][I]
[I] --> [number][I]
[I] --> ['+'][J]
[I] --> ['-'][J]
[J] --> [number][J]
[J] --> ['.'][K]
[J] --> [number][K]
[K] --> [number][K]
[K] --> ['i'][L]
[L] --> [final]
[START] --> ['='][M]
[M] --> [final]
[M] --> ['='][X]
[X] --> [final]
[START] --> ['<'][N]
[Y] --> [final]
[N] --> ['<'][Y]output.txt
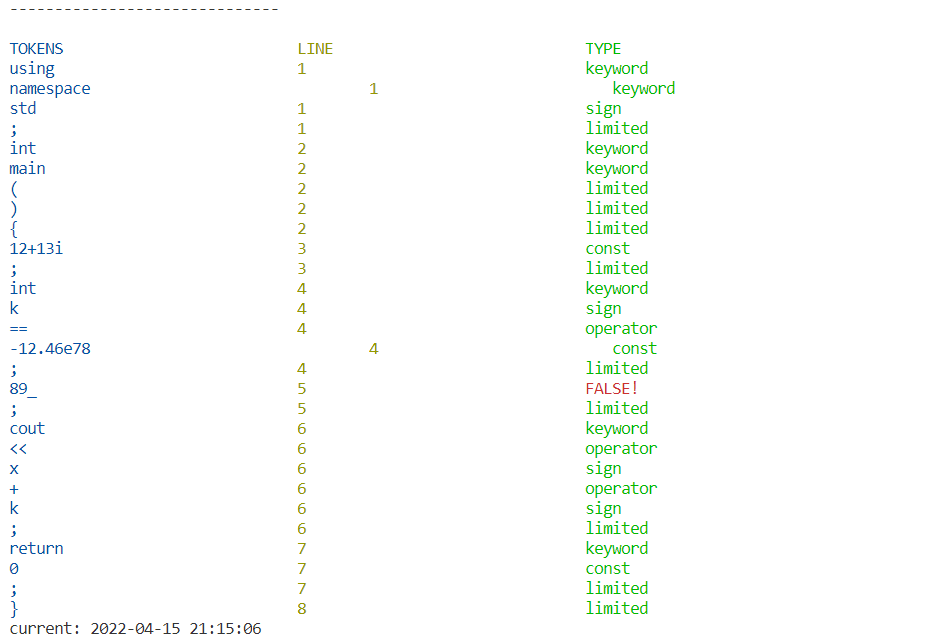
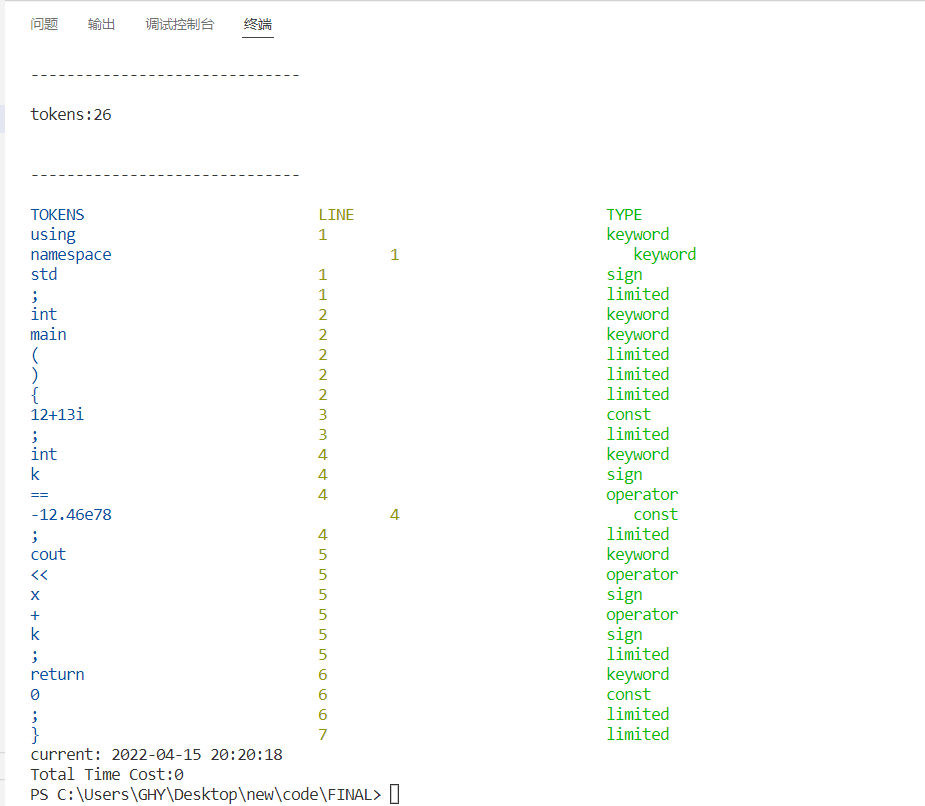
1 using keyword
1 namespace keyword
1 std sign
1 ; limited
2 int keyword
2 main keyword
2 ( limited
2 ) limited
2 { limited
3 12+13i const
3 ; limited
4 int keyword
4 k sign
4 == operator
4 -12.46e78 const
4 ; limited
5 cout sign
5 << operator
5 x sign
5 + operator
5 k sign
5 ; limited
6 return keyword
6 0 const
6 ; limited
7 } limited实验结果